AWS: Data Lake vs Data Warehouse – When to Choose What?
Introduction
In the world of modern data architecture, Data Lakes and Data Warehouses are often confused. Both are used to store and analyze data, but they serve very different purposes. Choosing the right one can save costs, improve performance, and set your business up for smarter decisions.
What is a Data Lake?
- Definition: A centralized repository that stores raw, unstructured, and semi-structured data (like logs, images, IoT streams).
- AWS Example: Amazon S3 as the storage layer + AWS Glue for cataloging.
- Use Case: When you need to store massive amounts of diverse data for future exploration or ML training.
What is a Data Warehouse?
- Definition: A structured repository designed for analyzing processed, relational data optimized for reporting and dashboards.
- AWS Example: Amazon Redshift.
- Use Case: When you need fast queries, analytics, and business intelligence reports.
Key Differences at a Glance:
| Feature | Data Lake (AWS S3) | Data Warehouse (AWS Redshift) |
|---|---|---|
| Data Type | Raw, unstructured, semi-structured | Structured, relational |
| Cost | Low storage cost, higher processing | Higher storage cost, optimized queries |
| Performance | Flexible but slower queries | Fast queries on structured data |
| Best For | Big data, ML/AI workloads | Business intelligence, dashboards |
| Schema | Schema-on-read | Schema-on-write |
Diagram: Data Flow from Sources to Data Lake and Warehouse
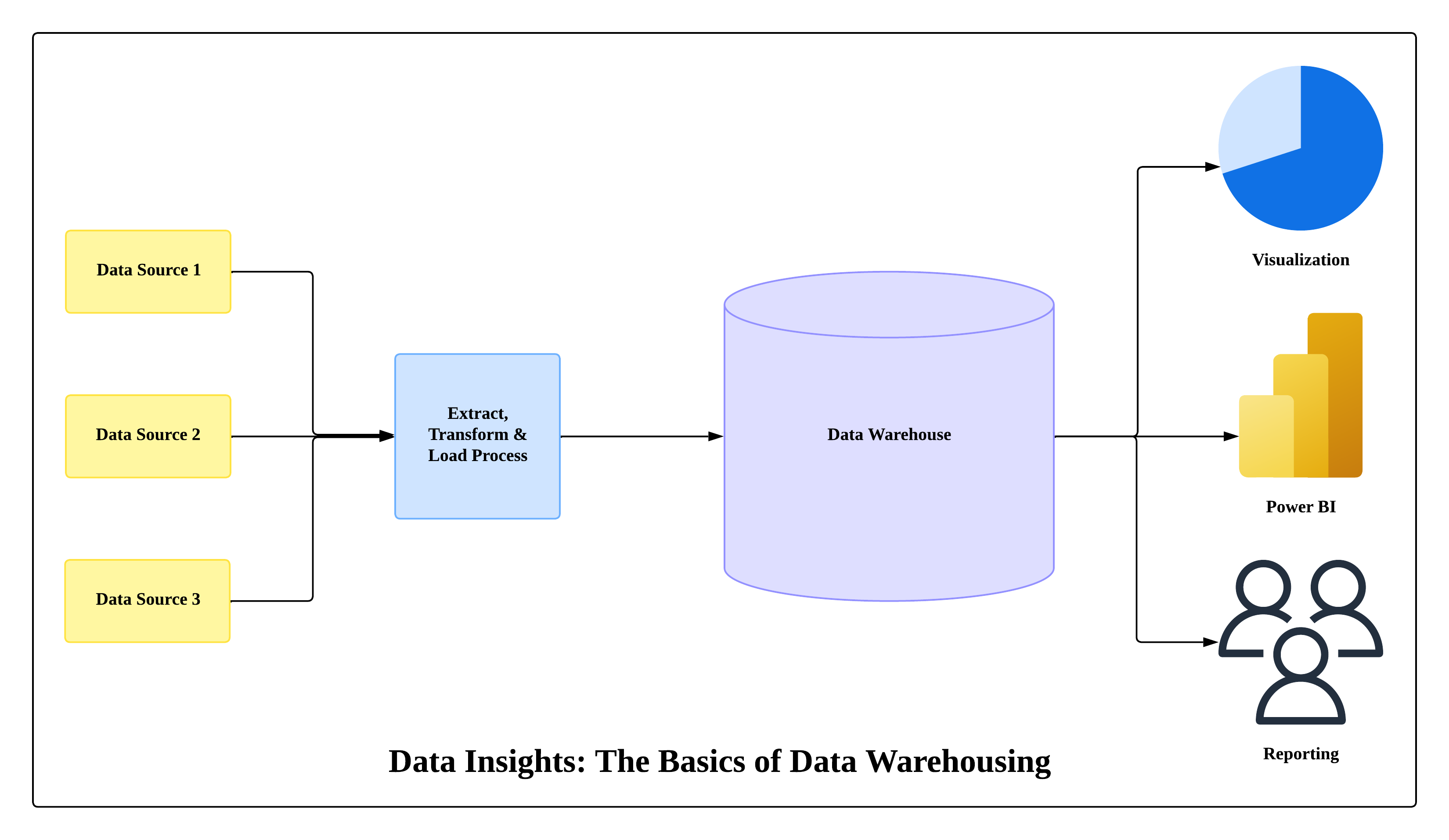
Figure: Raw data flows into a Data Lake (e.g., Amazon S3) and, after processing, structured data moves into a Data Warehouse (e.g., Amazon Redshift) for analytics.
When to Use Which?
- Choose a Data Lake if:
- You’re collecting raw logs, IoT data, or social media feeds.
- You want flexibility for future use cases like ML or advanced analytics.
- Choose a Data Warehouse if:
- You’re focused on dashboards, reports, and decision-making.
- Your data is structured and you prioritize query performance.
- Hybrid Approach (Lakehouse):
- Many organizations combine both: storing raw data in S3 (Data Lake), transforming it, and pushing structured data into Redshift (Warehouse).
Pro Tip
Don’t think of it as Data Lake vs Warehouse. In most modern AWS setups, both work together—with the data lake as a staging ground and the warehouse as the analytics layer.
Takeaway
Data Lakes and Data Warehouses are complementary, not competitors. Use a Data Lake for scale and flexibility, and a Data Warehouse for fast insights. Together, they enable a robust and future-proof data strategy.
References / Further Reading
Comments
Add Your Comment
Related Posts

AWS in Production: AWS Cost Anomalies — Detecting Spikes Before Finance Does
0 23
AWS in Production: Cloud Governance — Balancing Speed, Cost, and Control
0 28
AWS Architecture: Multi-Region Data Consistency — What Breaks First
0 87AI Foundations Bundle — From AI Basics to Deep Learning & NLP
Learn AI the right way — from core concepts to deep learning and language models, all in one structured bundle.
Ideal for beginners and developers who want a complete AI roadmap without confusion.
No comments yet. Be the first to comment!