Data Insights: Data Lake vs Data Warehouse – Key Differences
Introduction
In the data-driven world, organizations collect vast amounts of information from multiple sources — applications, sensors, social media, transactions, and logs.
But storing that data effectively, and analyzing it efficiently, depends on choosing the right architecture.
Two of the most common terms you’ll hear are Data Lake and Data Warehouse.
Though they sound similar, their purpose, structure, and usage differ significantly.
This guide explains how they work, where each excels, and how to decide which is best suited for your analytics strategy.
What Is a Data Lake?
A Data Lake is a centralized repository that stores raw, unprocessed data — structured, semi-structured, or unstructured — at any scale.
It’s built on the principle of “store now, process later.”
Data is ingested in its native format (CSV, JSON, logs, videos, sensor data, etc.) and transformed only when needed for analysis.
Typical technologies:
- AWS S3, Azure Data Lake Storage (ADLS), Google Cloud Storage
- Apache Hadoop, Databricks Lakehouse, Snowflake’s Iceberg
Key traits:
- Schema-on-read (structure applied only when querying)
- Low-cost storage for large data volumes
- Flexibility for AI, ML, and real-time analytics
Use case: Ideal for data scientists and engineers exploring raw data for modeling, predictions, and advanced analytics.
What Is a Data Warehouse?
A Data Warehouse is a curated, structured data store optimized for fast querying and business reporting.
It follows a schema-on-write approach — data is cleaned, transformed, and loaded into predefined tables before analysis.
Common platforms:
- Amazon Redshift, Google BigQuery, Snowflake, Azure Synapse Analytics
Key traits:
- High-performance SQL querying
- Enforced schema for consistency
- Optimized for dashboards and BI tools (e.g., Power BI, Tableau, Looker)
Use case: Perfect for business analysts and executives who need accurate, aggregated insights for decision-making.
Key Differences Between Data Lakes and Data Warehouses
| Feature | Data Lake | Data Warehouse |
|---|---|---|
| Data Type | Raw, structured, semi-structured, unstructured | Structured, processed |
| Schema | Schema-on-read | Schema-on-write |
| Purpose | Data exploration, ML, real-time analytics | Business intelligence, reporting |
| Users | Data engineers, data scientists | BI analysts, business users |
| Performance | Flexible but may require heavy compute | High-speed queries on refined data |
| Cost | Low storage cost, higher processing cost | Higher storage cost, optimized compute |
| Tools | Hadoop, Spark, Databricks | Snowflake, BigQuery, Redshift |
| Governance | Complex due to raw data | Strong and enforced |
| Storage Format | Object storage (S3, ADLS, GCS) | Relational storage (SQL-based) |
Data Lake vs Data Warehouse: Comparison Overview
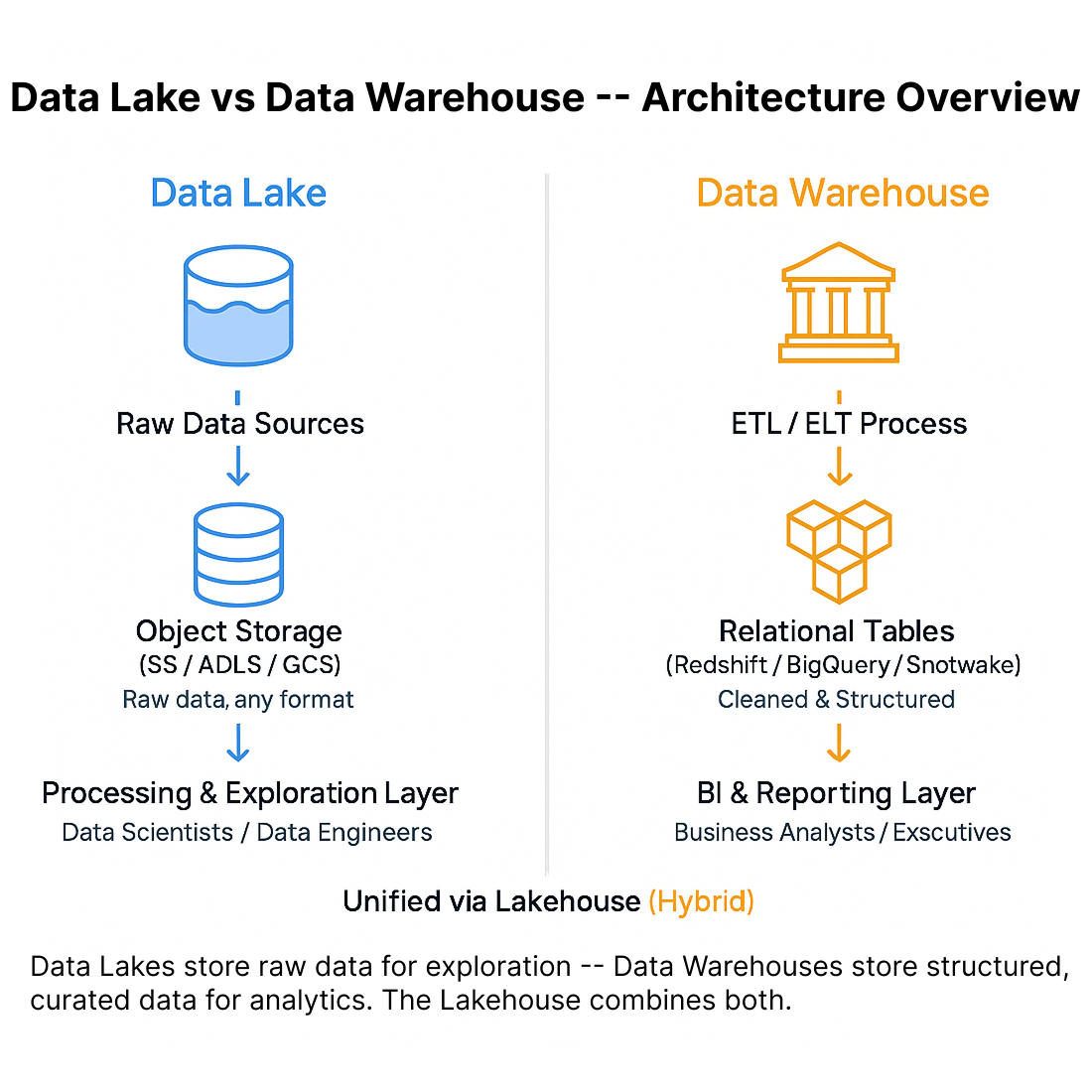
Figure: Data Lake vs Data Warehouse: Comparison Overview
When to Use a Data Lake
Choose a Data Lake if you:
- Need to store massive, varied datasets for long-term use.
- Plan to perform machine learning, data mining, or exploratory analysis.
- Want to integrate data streams from IoT devices, APIs, or click logs.
- Require cost-effective storage that scales easily.
Example: A retail company capturing customer clickstream data, product images, and transactions for AI-based recommendation models.
When to Use a Data Warehouse
Opt for a Data Warehouse if you:
- Need consistent, structured data for dashboards and analytics.
- Require fast SQL querying and reporting for leadership.
- Have clearly defined metrics (e.g., revenue, churn, sales performance).
- Want to enforce strict governance and access controls.
Example: A financial institution tracking daily revenue trends, KPIs, and forecasting through Tableau dashboards.
The Hybrid Future: Lakehouse Architecture
Modern data ecosystems are converging into a Lakehouse — combining the best of both worlds:
- The scalability and flexibility of a data lake
- The performance and reliability of a warehouse
Platforms like Databricks Lakehouse and Snowflake now enable analytics on raw and structured data using unified storage layers such as Delta Lake or Apache Iceberg.
This hybrid approach allows teams to avoid data silos and streamline the entire data lifecycle, from ingestion to AI/ML pipelines.
Choosing the Right Solution
| Organization Type | Recommended Approach |
|---|---|
| Startups or small teams | Data Lake for cost-efficiency and scalability |
| Mid-size analytics teams | Combination (Lake + Warehouse) |
| Large enterprises | Lakehouse or multi-tier data platform |
Ultimately, the choice depends on your use case, data maturity, and business goals.
Many organizations start with a data lake, evolve toward a warehouse for structured needs, and finally integrate both through a Lakehouse architecture.
Conclusion
Both Data Lakes and Data Warehouses are foundational pillars of modern analytics, but they serve distinct purposes.
A Data Lake gives flexibility and scale for innovation, while a Data Warehouse ensures reliability and insight for operations.
The future lies in architectures that combine their strengths — delivering fast, governed, and intelligent data ecosystems ready for AI-driven decisions.
References
Comments
Add Your Comment
Related Posts

Data Insights: Python in the Modern Data Stack – From ETL to AI Pipelines
0 42
Data Insights: Data Contracts – Fixing the Broken Data Pipeline Problem
0 56
Data Insights: Serverless Data Pipelines – AWS Lambda + S3 + Glue in Action
0 94
7-Day AI Crash Course
Learn how AI works, explore real-world examples, and build your first smart models step-by-step.
Perfect for beginners, students, and tech enthusiasts ready to start their AI journey.
No comments yet. Be the first to comment!