Architecture Insights: Architecture Patterns for Real-Time Data Processing
Introduction
Real-time data processing has become a core requirement for modern digital platforms.
From fraud detection systems to IoT analytics, streaming dashboards, and personalized recommendations, organizations rely on the ability to ingest, process, and react to data within milliseconds or seconds.
Traditional batch processing systems are no longer enough.
To support today’s event-driven systems, teams need scalable real-time architectures that can handle continuous, high-velocity data streams.
This blog explores the most widely used architecture patterns for real-time data processing — their strengths, applications, and trade-offs.
The Need for Real-Time Architectures
Real-time systems provide organizations with:
- Immediate insights for operational decision-making
- Faster reaction to anomalies
- Low-latency customer experiences
- Scalable ingestion from millions of devices
- Support for continuous event-driven workflows
Industries such as finance, e-commerce, cybersecurity, logistics, and streaming platforms rely heavily on real-time processing to remain competitive.
Core Components in a Real-Time Pipeline
Before exploring patterns, it’s important to understand the building blocks:
Data Ingestion
Tools like Kafka, Kinesis, Pulsar, or MQTT provide persistent, high-throughput event ingestion.
Stream Processing
Frameworks like Apache Flink, Spark Structured Streaming, and Kinesis Analytics allow transforming, aggregating, and enriching streaming data.
Storage Layers
Depending on the use case:
- Hot path: Redis, DynamoDB, Cassandra
- Warm path: Elasticsearch, ClickHouse
- Cold path: S3, Snowflake, BigQuery
Serving / Query Layer
Provides dashboards, APIs, and user-facing responses:
- Precomputed views
- Real-time APIs
- Materialized aggregates
Architecture Pattern 1: Lambda Architecture
Lambda Architecture combines batch processing and real-time (speed) processing to achieve both accuracy and low latency.
How it Works
- Batch layer computes accurate historical views using large datasets.
- Speed layer computes incremental, real-time updates.
- Serving layer merges batch + speed results.
When to Use
- When accuracy is important but low-latency is also needed.
- Analytics-heavy domains like finance or e-commerce.
Trade-offs
- Two code paths → complexity doubles.
- Higher operational overhead.
Architecture Pattern 2: Kappa Architecture
Kappa Architecture simplifies Lambda by removing the batch layer entirely.
Everything is processed as a stream.
How it Works
- A unified pipeline processes data continuously.
- Reprocessing is done by replaying events from Kafka or other logs.
When to Use
- When batch is not required.
- IoT, anomaly detection, recommendation pipelines.
Trade-offs
- Requires a durable, replayable log (e.g., Kafka).
- High dependency on stream processing infrastructure.
Kappa Architecture – Reference Diagram
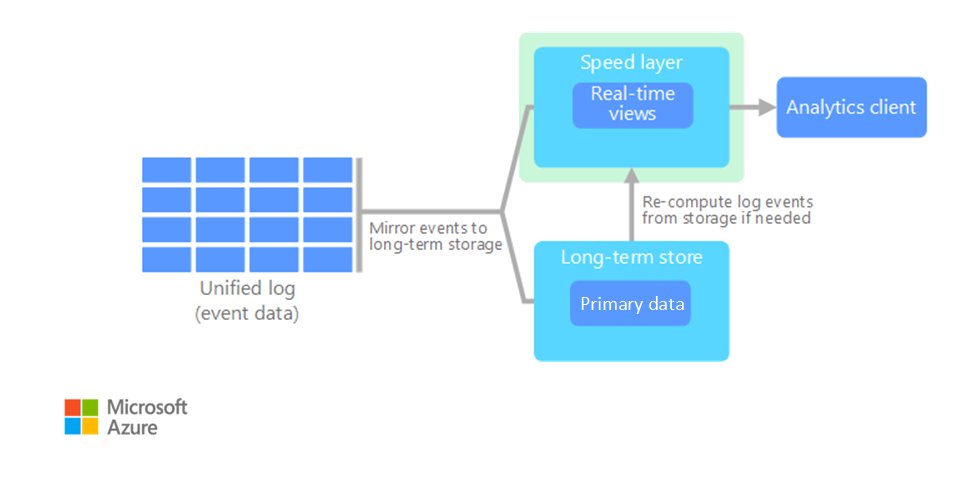
Figure: Kappa Architecture illustrating a unified, stream-only processing pipeline without a batch layer. This is the second diagram on the reference page.
Architecture Pattern 3: Event-Driven Microservices
In this pattern, microservices communicate using events instead of synchronous APIs.
How it Works
- Services emit events to Kafka, SNS, EventBridge, or Pulsar.
- Other services react asynchronously to these events.
When to Use
- E-commerce platforms
- Financial systems
- Large distributed systems with decoupled teams
Trade-offs
- Requires strong observability and traceability.
- Event versioning and schema management become critical.
Architecture Pattern 4: Hot Path / Cold Path (Speed + Batch)
This is a common real-time analytics pattern.
How it Works
- Hot path: low-latency computation using in-memory or streaming engines.
- Cold path: long-term storage and historical computation using batch systems.
When to Use
- Dashboards that combine recent and historical insights (e.g., real-time BI).
- IoT monitoring.
Trade-offs
- Requires synchronization between hot and cold stores.
- Duplicate logic across layers.
Hot Path and Cold Path Architecture – Reference Diagram
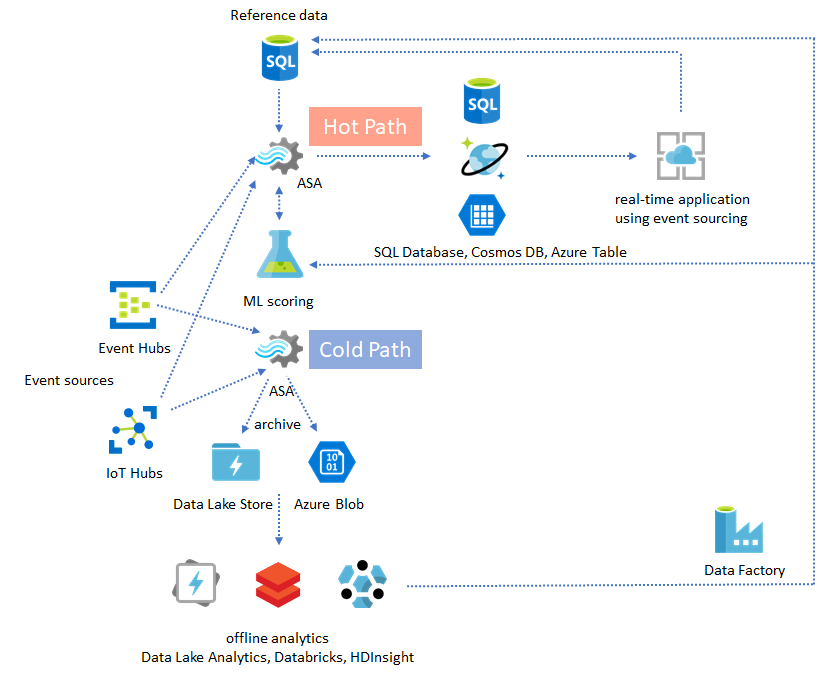
Figure: Hot path and cold path processing model for real-time and batch analytics. This is the primary diagram of the Hot/Cold pattern section.
Architecture Pattern 5: CQRS for Real-Time Systems
CQRS (Command Query Responsibility Segregation) separates write and read workloads.
How it Works
- Write model handles commands and updates.
- Read model maintains precomputed, real-time views.
When to Use
- Systems with heavy read load
- Leaderboards
- Analytics dashboards
- Inventory or order management systems
Trade-offs
- Requires eventual consistency management
- Needs robust event sourcing or replication
CQRS Pattern – Command and Query Segregation Diagram

Figure: CQRS pattern illustrating separate command and query models with distinct write and read stores. This is the main diagram on the CQRS pattern page.
Architecture Pattern 6: Stream Processing with Stateful Operators
Modern stream processors maintain state inside the pipeline.
How it Works
- Frameworks like Flink or Kafka Streams store aggregated state locally.
- State is periodically checkpointed to distributed stores.
When to Use
- Sliding windows, tumbling windows, session windows
- Fraud detection
- Rate limiting
- Anomaly scoring
Trade-offs
- Requires careful state management
- Needs durable checkpointing to avoid data loss
Stateful Stream Processing – Checkpointing Diagram

Figure: Flink checkpointing model showing checkpoint barriers flowing through parallel operators and creating consistent, recoverable state snapshots.
Choosing the Right Pattern
The right architecture depends on:
- Latency requirements
- Data volume and velocity
- Accuracy vs immediacy
- Operational overhead
- Cost considerations
- Tooling and team expertise
Lambda and Kappa remain dominant in analytics pipelines.
Event-driven systems are favored for microservice ecosystems.
Hot-Cold patterns support BI and dashboards.
Stateful stream processing powers anomaly detection and ML in real time.
Conclusion
Real-time data processing is no longer a niche requirement — it is fundamental to building responsive, intelligent, and scalable systems.
By understanding the architecture patterns behind real-time pipelines, teams can design systems that are efficient, reliable, and ready for future growth.
Selecting the right pattern is not about choosing the most sophisticated one, but the one that aligns with your system’s latency, accuracy, and operational needs.
References
Comments
Add Your Comment
Related Posts

Architecture Realities: Why Simpler Architectures Often Win at Scale
0 30
Architecture Realities: Designing Systems for Teams, Not Just Traffic
0 70
Architecture Realities: Scaling Isn’t the Hard Part – Maintaining Systems Is
0 69
7-Day AI Crash Course
Learn how AI works, explore real-world examples, and build your first smart models step-by-step.
Perfect for beginners, students, and tech enthusiasts ready to start their AI journey.
No comments yet. Be the first to comment!