🧠 AI with Python - 🌳 Train a Decision Tree Classifier on Iris Dataset.
Posted on: August 5, 2025
Description:
Decision Trees are one of the simplest yet powerful algorithms for classification tasks. In this post, we train a Decision Tree Classifier using Python and the popular Iris dataset.
Why the Iris Dataset?
The Iris dataset is widely used for learning classification because:
- It has only 150 samples and 4 features (sepal length, sepal width, petal length, petal width).
- The goal is to classify iris flowers into one of three species: Setosa, Versicolor, Virginica.
- It’s easy to visualize and interpret.
How the Model Works
- Loading the Dataset: We use scikit-learn’s built-in Iris dataset.
- Training the Model: A Decision Tree Classifier is trained to learn how feature values map to specific flower species.
- Visualizing the Tree: The resulting tree structure shows how decisions are made based on threshold splits of features.
Results
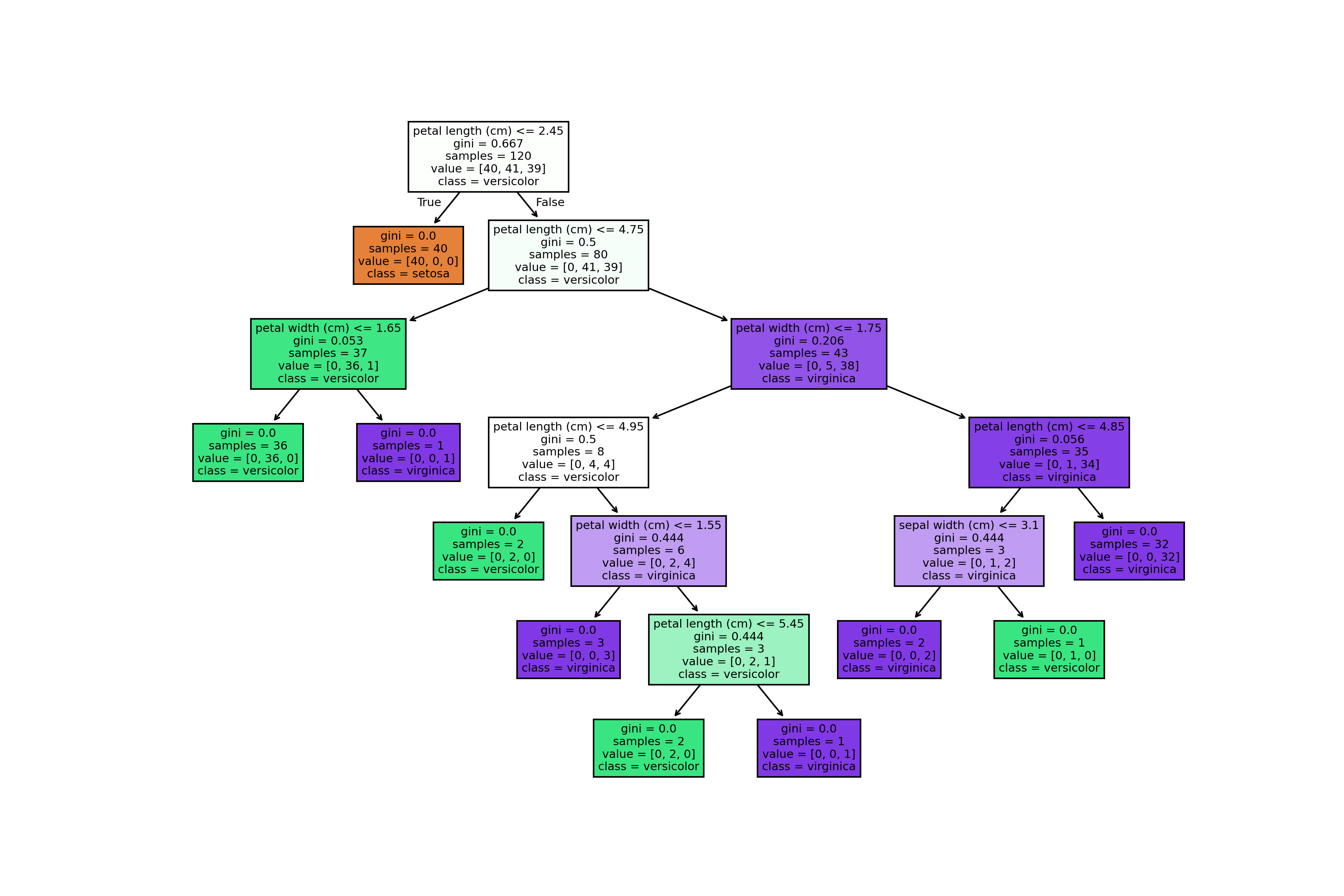
Figure: Decision Tree Visualization
Key Takeaways
- Decision Trees are intuitive and easy to explain to stakeholders.
- They can handle numerical and categorical features without complex preprocessing.
- Visualization helps you understand how the model makes predictions.
Code Snippet:
# Import required libraries
from sklearn.datasets import load_iris # To load Iris dataset
from sklearn.tree import DecisionTreeClassifier, plot_tree # Model + visualization
from sklearn.model_selection import train_test_split # For splitting data
from sklearn.metrics import accuracy_score # To evaluate model
import matplotlib.pyplot as plt
import pandas as pd
# Load the Iris dataset
iris = load_iris()
# Convert to DataFrame
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
# Display first 5 rows
df.head()
# Features and labels
X = iris.data
y = iris.target
# Split into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
print("Training data shape:", X_train.shape)
print("Testing data shape:", X_test.shape)
# Initialize the Decision Tree classifier
dt_clf = DecisionTreeClassifier(random_state=42)
# Fit model
dt_clf.fit(X_train, y_train)
print("Model training complete!")
# Make predictions
y_pred = dt_clf.predict(X_test)
# Evaluate accuracy
accuracy = accuracy_score(y_test, y_pred)
print(f"Decision Tree Accuracy: {accuracy * 100:.2f}%")
# Visualize decision tree
plt.figure(figsize=(12, 8))
plot_tree(dt_clf, feature_names=iris.feature_names, class_names=iris.target_names, filled=True)
plt.show()Link copied!
Comments
Add Your Comment
Comment Added!
Related Posts

🧠 AI with Python – 📊 Reliability Diagrams

🧠 AI with Python – 📈 Model Calibration Curves

🧠 AI with Python – 🔥 Feature Interaction Heatmaps

7-Day AI Crash Course
Learn how AI works, explore real-world examples, and build your first smart models step-by-step.
Perfect for beginners, students, and tech enthusiasts ready to start their AI journey.
No comments yet. Be the first to comment!